HBM 4,即將完成
日前,JEDEC固態技術協會宣布,備受期待的高帶寬存儲器 (HBM) DRAM 標准的下一個版本:HBM4 即將完成。
據介紹,HBM4 是目前發布的 HBM3 標准的進化版,旨在進一步提高數據處理速率,同時保持基本特性,例如更高的帶寬、更低功耗和更大的每個芯片和/或堆棧容量。這些進步對於需要高效處理大數據集和復雜計算的應用至關重要,包括生成人工智能 (AI)、高性能計算、高端顯卡和服務器。
與 HBM3 相比,HBM4 計劃將每個堆棧的通道數增加一倍,物理佔用空間也更大。爲了支持設備兼容性,該標准確保單個控制器可以在需要時同時與 HBM3 和 HBM4 配合使用。不同的配置將需要不同的中介層來適應不同的佔用空間。HBM4 將指定 24 Gb 和 32 Gb 層,並可選擇支持 4 高、8 高、12 高和 16 高 TSV 堆棧。
JEDEC指出,委員會已就高達 6.4 Gbps 的速度等級達成初步協議,目前正在討論更高的頻率。
HBM 4,有哪些更新?
高帶寬內存已存在約十年,在其持續發展過程中,其速度穩步提升,數據傳輸速率從 1 GT/s(最初的 HBM)开始,到現在HBM3E的9 GT/s。這使得帶寬在不到 10 年的時間裏實現了令人矚目的飛躍,使 HBM 成爲此後投放市場的全新 HPC 加速器的重要基石。
但隨着內存傳輸速率的提高,尤其是在 DRAM 單元的基本物理特性沒有改變的情況下,這種速度也越來越難以維持。因此,對於 HBM4,該規範背後的主要內存制造商正計劃對高帶寬內存技術進行更實質性的改變,從更寬的 2048 位內存接口开始。
HBM4 將把內存堆棧接口從1024 位擴展至 2048 位,這將是自八年前推出這種內存類型以來 HBM 規範最重要的變化之一。將 I/O 引腳數量增加兩倍,同時保持相似的物理佔用空間,對於內存制造商、SoC 开發商、代工廠和外包組裝和測試 (OSAT) 公司來說極具挑战性。

按照計劃,這將使 HBM4 在多個層面上實現重大技術飛躍。在 DRAM 堆疊方面,2048 位內存接口將需要顯著增加通過內存堆棧布线的硅通孔數量。同時,外部芯片接口將需要將凸塊間距縮小到 55 微米以下,同時將微凸塊總數從 HBM3 的當前數量(約)3982 個凸塊大幅增加。
內存制造商表示,他們還將在一個模塊中堆疊多達 16 個內存芯片,即所謂的 16-Hi 堆疊,這爲該技術增加了一些復雜性。(HBM3 在技術上也支持16-Hi 堆疊,但到目前爲止還沒有制造商真正使用它)這將允許內存供應商顯著增加其 HBM 堆棧的容量,但它帶來了新的復雜性,即在無缺陷的情況下連接更多數量的 DRAM 芯片,然後保持最終的 HBM 堆棧適當且一致地短。而所有這一切反過來又需要芯片制造商、內存制造商和芯片封裝公司之間更加緊密的合作,以使一切順利進行。
不過,隨着DRAM堆棧數量的增加,有人指出封裝技術面臨着局限性。
現有的HBM採用了TC(熱壓)鍵合技術,該技術在DRAM中創建TSV通道,並通過小突起形式的微凸塊進行電連接。三星電子和海力士的具體方法有所不同,但相似之處在於都使用了凸點。
最初,客戶將 DRAM 堆疊至多達 16 層,並要求 HBM4 最終封裝厚度爲 720 微米,與前幾代產品相同。普遍的觀點是,使用現有的接合實際上不可能在 720 微米處實現 16 層 DRAM 堆疊 HBM4。因此,業界關注的替代方案是混合鍵合。混合鍵合是一種在芯片和晶圓之間直接鍵合銅布线的技術。由於DRAM之間不使用凸塊,因此更容易減小封裝厚度。
然而,據韓國媒體在三月的報道,在當時的討論中,相關公司決定將封裝厚度標准放寬至775微米(μm),比上一代的720微米(μm)更厚。國際半導體標准組織(JEDEC)的主要參與者也同意將HBM4產品的標准定爲775微米。如果封裝厚度減少到775微米,即使使用現有的接合技術,也可以充分實現16層DRAM堆疊HBM4。考慮到混合鍵合的投資成本巨大,存儲器公司很可能將重點放在升級現有鍵合技術上。
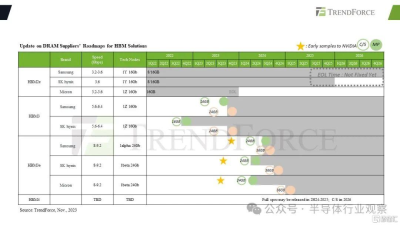
根據Trendforce 去年年底分享的路线圖預計,首批 HBM4 樣品預計每堆棧容量高達 36 GB,完整規格預計將由 JEDEC 在 2024-2025 年下半年左右發布。預計第一批客戶樣品和供貨時間是 2026 年,因此我們還有很長一段時間才能看到新的高帶寬內存解決方案投入使用。
三大巨頭的最新布局
目前,市場上有SK Hynix、三星和美光這三大玩家,他們在HBM 4上也明爭暗鬥。
首先看SK Hynix方面,在五月的一次行業活動中表示,SK Hynix 表示,可能在 2025 年率先推出下一代 HBM4。SK Hynix 計劃在 HBM4 的基礎芯片中採用台積電的先進邏輯工藝,以便將額外的功能塞進有限的空間內,幫助 SK Hynix 定制 HBM,以滿足更廣泛的性能和能效要求。
與此同時,SK 海力士表示,雙方還計劃致力於優化其 HBM 和晶圓上芯片 (CoWoS,台積電的封裝技術) 技術的組合,並滿足客戶的 HBM 需求。

在SK海力士看來,公司的HBM產品具備業界最佳的速度和性能。尤其是我們獨有的MR-MUF技術,爲高性能提供了最穩定的散熱,爲造就全球頂尖性能提供了保障。SK 海力士聲稱,大規模回流成型底部填充 (MR-MUF) 技術制造,比使用熱壓縮非導電膜(TC-NCF) 制造的產品堅固 60%。此外,公司擁有快速量產優質產品的能力,我們對客戶需求的響應速度也是首屈一指的。這些競爭優勢的結合使公司的HBM脫穎而出,躋身行業前列。
具體到DRAM方面,據報道,SK海力士計劃將1b DRAM應用到HBM4,並從HBM4E應用1c DRAM。但據了解,SK海力士仍留有根據市場情況靈活改變應用技術的空間。
來到三星方面,作爲一個追趕者,三星也火力全开。
三星電子在其設備解決方案 (DS) 部門內成立了新的“HBM 开發團隊”,以增強其在高帶寬內存 (HBM) 技術方面的競爭力。這一战略舉措是在副董事長 Kyung-Hyun Kyung 就任 DS 部門負責人一個多月後採取的,反映了該公司致力於在快速發展的半導體市場中保持領先地位的決心。
新成立的 HBM 开發團隊將專注於推進 HBM3、HBM3E 和下一代 HBM4 技術。該計劃旨在滿足人工智能 (AI) 市場擴張帶來的對高性能內存解決方案的激增需求。今年早些時候,三星已經成立了一個工作組 (TF) 來增強其 HBM 競爭力,新團隊將整合和提升這些現有的努力。
三星電子同時強調,將加強其定於明年發布的第六代高帶寬內存(HBM4)的定制服務。
該公司內存事業本部新業務規劃組副總裁Choi Jang-seok表示:“與HBM3相比,HBM4的性能顯着提高”,並補充說:“我們正在擴大產能到 48GB(千兆字節)並以明年的生產目標進行开發。”
三星電子將MOSFET工藝應用到HBM3E,並正在積極考慮從HBM4开始應用FinFET工藝。因此,與 MOSFET 應用相比,HBM4 的速度提高了 200%,面積縮小了 70%,性能提高了 50% 以上。這是三星電子首次公开HBM4規格。
Choi 副總裁表示:“HBM 架構將發生重大變化。許多客戶的目標是定制優化,而不是現有的通用用途。”他補充道,“例如,HBM DRAM 和定制邏輯芯片的 3D 堆疊顯著提高。” “由於通用 HBM 的中介層和大量輸入/輸出 (I/O),將有可能降低性能並消除性能擴展的障礙,”他解釋道。
他繼續說道,“HBM不僅不能忽視性能和容量,還不能忽視功耗和熱效率。爲此,16層HBM4不僅採用了NCF之外的HCB(混合鍵合)技術等各種尖端封裝技術(非導電粘合膜)組裝技術,還有新工藝“正確實施各種新技術至關重要,三星正在按照計劃進行准備,”他補充道。
有報道指出,三星電子最近在內部制定了一項計劃,將原來計劃安裝在HBM4中1b DRAM改爲1c DRAM。並將量產目標日期從明年年底提前到明年中下旬,但因爲良率必須得到支持,此傳言尚未得到證實。
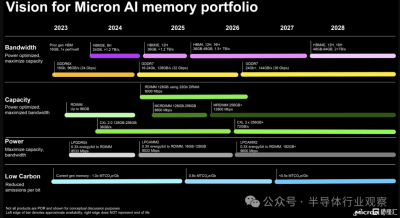
另一家HBM參與者美光則預計在2025到2026年推出12H和16H的HBM4,其容量爲 36GB 到 48GB ,速度爲1.5TB/S以上。據美光稱,HBM4 之後,HBM4E 將於 2028 年問世。HBM4 的擴展版本預計將獲得更高的時鐘頻率,並將帶寬提高到 2+ TB/s,容量提高到每個堆棧 48GB 到 64GB。
將高帶寬內存加速至光速
HBM 的出現是爲了向 GPU 和其他處理器提供比標准 x86 插槽接口所能支持的更多的內存。但 GPU 的功能越來越強大,需要更快地從內存中訪問數據,以縮短應用程序處理時間——例如,大型語言模型 (LLM) 可能涉及在機器學習訓練運行中重復訪問數十億甚至數萬億個參數,而這可能需要數小時或數天才能完成。
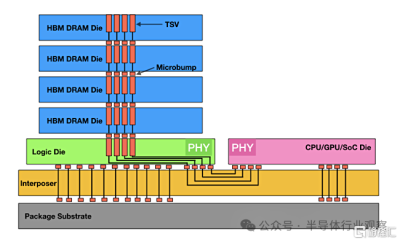
當前的 HBM 遵循相當標准的設計:HBM 內存堆棧通過微凸塊連接到位於基礎封裝層上的中介層,微凸塊連接到 HBM 堆棧中的硅通孔 (TSV 或連接孔)。中介層上還安裝了一個處理器,並提供 HBM 到處理器的連接
HBM 供應商和 HBM 標准機構正在研究使用光子學等技術或直接將 HBM安裝在處理器芯片上來加快 HBM 到處理器的訪問速度。供應商正在設定 HBM 帶寬和容量速度——似乎比 JEDEC 標准機構能夠跟上的速度更快。
三星正在研究在中介層中使用光子技術,光子在鏈路上的流動速度比編碼爲電子的比特速度更快,而且功耗更低。光子鏈路可以以飛秒的速度運行。這意味着10-15單位時間——一千萬億分之一秒(十億分之一的百萬分之一)。

據韓國媒體報道,SK 海力士還在研究直接 HBM-邏輯連接概念。這一概念將 GPU 芯片與 HBM 芯片一起制造在混合用途半導體中。該芯片廠將此視爲 HBM4 技術,並正在與 Nvidia 和其他邏輯半導體供應商進行談判。這個想法涉及內存和邏輯制造商共同設計芯片,然後由台積電等晶圓廠運營商制造。
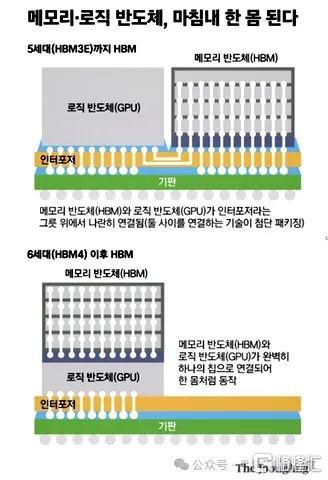
這有點類似於內存處理(PIM)的想法,除非受到行業標准的保護,否則將是專有的,具有供應商鎖定的前景。
與三星和 SK 海力士不同,美光並未談論將 HBM和邏輯集成到單個芯片中。它將告訴 GPU 供應商(AMD、英特爾和 Nvidia),他們可以使用組合的 HBM-GPU 芯片獲得更快的內存訪問速度,而 GPU 供應商將非常清楚專有鎖定和單一來源的危險。
隨着 ML 訓練模型越來越大,訓練時間越來越長,通過加快內存訪問速度和增加每個 GPU 內存容量來縮短運行時間的壓力也將同步增加。放棄標准化 DRAM 的競爭供應優勢,獲得鎖定的 HBM-GPU 組合芯片設計(盡管速度和容量更好)可能不是前進的正確方法。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:HBM 4,即將完成
地址:https://www.twnewsletter.com/article/44434.html