GPU,獨孤求敗?
據台媒報道,台積電近期准備开始生產英偉達最新Blackwell平台架構GPU,同時因英偉達的客戶需求強勁,故此對台積電的晶圓訂單增加25%;並有可能令本周放榜的台積電上調今年盈利預期。
報道引述業界消息指出,亞馬遜、戴爾、谷歌、Meta及微軟等都會使用Blackwell架構GPU來建立AI伺服器,令需求超出預期。
英偉達的利好,讓大家對人工智能、GPU和AI芯片有了更多的想法,但這能繼續持續嗎?
GPU,銷量咋樣?
近來,外媒nextplatform還對AI芯片的銷售做了預測。
外媒引述AMD CEO蘇姿豐的數據表示,到 2023 年,數據中心 AI 加速器的總潛在市場規模約爲 300 億美元,到 2027 年底,該市場將以約 50% 的復合年增長率增長至 1500 億美元以上。但一年後,隨着 GenAI 熱潮的興起,以及 12 月推出“Antares”Instinct MI300 系列 GPU,蘇姿豐表示,AMD 預計 2023 年數據中心 AI 加速器市場規模將達到 450 億美元,到 2027 年,該市場將以超過 70% 的復合年增長率增長至 4000 億美元以上。
這僅適用於加速器,而不適用於服務器、交換機、存儲和軟件。
New Street Research 的 Pierre Ferragu 的團隊在科技領域做出了許多出色的工作,他曾嘗試分析這家價值 4000 億美元的數據中心加速器的潛在市場規模可能會如何,並在 Twitter 上發布了這一預測:
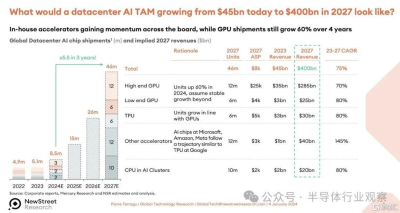
我們仍然認爲這是一個非常大的數字,預計在 TAM 預測期結束時 AI 服務器、存儲和交換機的銷售額將達到約 1 萬億美元。
在 2024 年伊始,我們從富國銀行股票研究公司董事總經理兼技術分析師 Aaron Rakers 那裏獲得了 GPU 銷售預測,並進行了一些電子表格操作。該模型涵蓋了 2015 年至 2022 年數據中心的 GPU 銷售情況,並估計到 2023 年結束(預測時尚未結束)並延伸到 2027 年。富國銀行的模型也早於AMD 最近幾個月做出的修訂預測,AMD 表示 2024 年的 GPU 銷售收入將達到 40 億美元。(我們認爲會是 50 億美元。)
無論如何,富國銀行的模型顯示,2023 年 GPU 銷售額將達到 373 億美元,全年出貨量爲 549 萬台。出貨量幾乎翻了一番——包括所有類型的 GPU,而不僅僅是高端 GPU。GPU 收入增長了 3.7 倍。預測 2024 年數據中心 GPU 出貨量爲 685 萬台,增長 24.9%,收入爲 487 億美元,增長 28%。2027 年預測 GPU 出貨量爲 1351 萬台,推動數據中心 GPU 銷售額達到 953 億美元。在該模型中,Nvidia 在 2023 年的收入市場份額爲 98%,到 2027 年僅下降到 87%。
Gartner 和 IDC 最近都發布了一些關於 AI 半導體銷售的數據和預測。
近一年前,Gartner 發布了一份關於 2022 年 AI 半導體銷售的市場研究報告,並預測了 2023 年和 2027 年的銷售情況,幾周前,它又發布了一份修訂後的預測報告,其中預測了 2023 年的銷售情況,並預測了 2024 年和 2028 年的銷售情況。第二份報告的市場研究報告中也包含一些統計數據,我們將其添加到下表中:
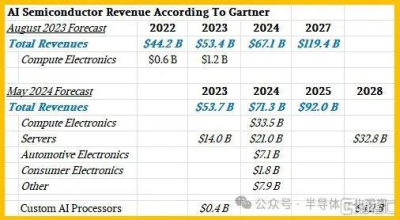
我們假設計算電子產品包括個人電腦和智能手機,但就連建立這些模型的 Gartner 副總裁兼分析師 Alan Priestly 也知道,到 2026 年,所有銷售的個人電腦芯片都將是人工智能個人電腦芯片,因爲所有筆記本電腦和台式機的 CPU 都將包含某種類型的神經網絡處理器。
用於加速服務器的 AI 芯片是我們在The Next Platform上關注的重點,這些芯片的收入(我們假設不包括附帶的 HBM、GDDR 或 DDR 內存的價值)在 2023 年爲 140 億美元,預計到 2024 年將增長 50%,達到 210 億美元。但預計 2024 年至 2028 年期間服務器 AI 加速器的復合年增長率僅爲 12% 左右,銷售額將達到 328 億美元。Priestly 表示,定制 AI 加速器(如 TPU 以及亞馬遜網絡服務的 Trainium 和 Inferentia 芯片)(僅舉兩個例子)在 2023 年僅帶來了 4 億美元的收入,到 2028 年也只會帶來 42 億美元的收入。
如果 AI 芯片佔計算引擎價值的一半,而計算引擎佔系統成本的一半,那么這些相對較小的數字加起來可能會帶來數據中心 AI 系統相當可觀的收入。同樣,這取決於 Gartner 在哪裏劃定界限,以及你認爲應該如何劃定界限。
現在,讓我們來看看 IDC 如何看待 AI 半導體和 AI 服務器市場。該公司幾周前發布了這張有趣的圖表:
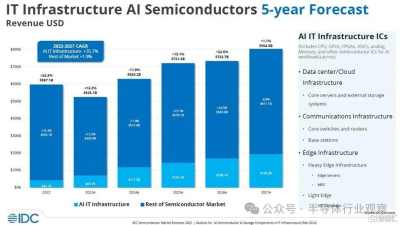
在此圖表中,IDC 匯總了數據中心和邊緣環境中使用的 CPU、GPU、FPGA、定制 ASIC、模擬設備、內存和其他芯片的所有收入。然後,它扣除了計算、存儲、交換機和其他設備的收入,因爲這些設備適用於 AI 訓練和 AI 推理系統。這不是所有系統的價值,而是系統中的所有芯片的價值;因此它不包括機箱、電源、冷卻、主板、轉接卡、機架、系統軟件等。如您所見,此圖表包含 2022 年的實際數據,並且仍在估算 2023 年至 2027 年的數據。
在 IDC 的分析中,半導體市場中的人工智能部分從 2022 年的 421 億美元增長到 2023 年的 691 億美元,這意味着 2022 年至 2023 年之間的增長率爲 64.1%。今年,IDC 認爲人工智能芯片收入——這不僅僅意味着 XPU 的銷售,還包括數據中心和邊緣人工智能系統中的所有芯片內容——將增長 70%,達到 1175 億美元。如果你計算 2022 年至 2027 年之間的數字,IDC 估計數據中心和人工智能系統中的人工智能芯片內容的物料清單總收入將以 28.9% 的復合年增長率增長,到 2027 年達到 1933 億美元。
由此看來,GPU似乎還是一致的贏家,但曾在英特爾工作的Raja Koduri最近發布了一篇文章,分析了GPU的影響。
GPU沒有對手?
首先,Raja Koduri先分享了一系列的公式。

接下來,他一步步分析了這些公式:

首先看上面這個公式,Raja Koduri強調,您可以將此等式應用於 CPU 架構,因爲這在設備、PC 和雲上都取得了成功。而對於 AI 和其他浮點 + 帶寬密集型工作負載,GPU 在此等式上得分最高 - 尤其是 CUDA GPU。而今天NVDA的天文估值就是一個很好的方程式形式。
在Raja Koduri看來,有抱負的競爭對手應該注意這個等式,並確定你的方法在你所針對的工作負載領域與現有企業的價值。
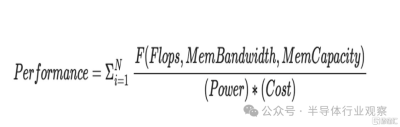
再看上面這個公式。
按照Raja Koduri所說,前面的西格瑪(sigma)表示每個工作負載。對於不同的型號/工作負載,浮點運點的比率、帶寬和容量要求可能不同。訓練與推理是生成不同比率的一個例子。
Raja Koduri同時強調,我們不要忘記,在推理和訓練循環之外,還有加速計算的需求 例如:圖像和語音處理以及衆所周知的並行數據分析和模擬算法。您的通用性會影響“N”的大小。此 N 對於 CUDA GPU 來說意義重大。對於 CPU 來說,N 甚至更大,但隨後等式的其余部分开始發揮作用,它們的性能弱點佔主導地位。
分子有 3 個參數 Flops、Bandwidth 和 Capacity。
Raja Koduri重申,Flop 需要通過寬度 (64,32,19, 16,8,4..) 和類型 (float, int..) 進行限定,工作負載可以混合使用這些。同樣,帶寬和容量也具有許多層次結構 - 寄存器、L1、L2、HBM、NVlink、以太網、NVME......
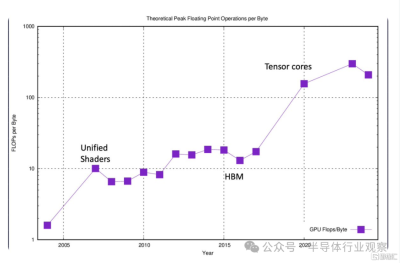
Raja Koduri在文章中還對現代 GPU 性能優化策略的簡要介紹。
他表示,當我們首次在 GPU 中引入浮點可編程着色器時,浮點運算與 DRAM 帶寬的比率爲 1:1。在最新的 GPU 上,對於 16 位甚至更高、精度更低的格式,該範圍超過 300:1。現在,對於更接近計算的內存(如寄存器、L1、L2 等)來說,這個比率變得更好。如果你研究一下最近關於轉換器的大多數優秀的GPU優化工作,它歸結爲最小化這個比例。使用關閉內存層的次數越多越好。
在Raja Koduri看來,其他策略包括利用未充分利用的浮點點數以異步(Async)方式運行下一個 ALU 受限階段。運氣和技巧在尋找漂亮的“overlappable”代碼塊方面起着重要作用,這些代碼塊不會破壞彼此的緩存。
不過Raja Koduri強調,異步不適合膽小的人。您可以對代碼進行的每一個百分點的flop-utilization改進都可能節省數十億美元。
其他常見問題包括——爲什么 CPU 人員不投入更多的 FLOPS 和 BANDWIDTH 並贏得 AI 战爭?是否存在基本的架構限制?
Raja Koduri表示,關於這個問題的簡單物理學答案是“否”。 但是,要將更多帶寬引入 CPU,需要對 CPU 結構基礎設施進行多次升級(和妥協)。一般來說,折衷方案是延遲。如果有人向您展示他們可以以更低的延遲、更低的功耗和成本提供更高的帶寬。那么尼可站起來,加入他們的宗教。
CPU 設計人員傾向於優先考慮延遲而不是帶寬,因爲通常根據延遲來判斷他們的工作負載集。像英特爾 Sapphire Rapids+HBM 這樣的產品提供了很好的帶寬提升,但不足以挑战 GPU。
接下來看下面與功耗和成本有關的公式:

首先看功耗方面,從圖中可以看到,Pj/Flop 在主流半導體工藝方面並沒有顯着改善。你唯一可以玩的遊戲是flop的定義,我們把它從64降低到4..現在可能是1.5。今天 FP16 的 pj/flop 在 0.5-0.7 的範圍內。
peta-flop GPU 的快速計算,10^15 * (0.7*10^-12) = 700 瓦。帶寬的功率計算起來有點棘手,並且可能會踩到供應商的一些專有信息,在這裏就不深入分析了。
Pj/Bit 是我看到架構師可以利用的重要 (10 倍) 機會的地方。我認爲本十年的下半年將看到許多有趣的嘗試,包括圍繞近內存、內存計算、共封裝光子學等的舉措。
再看成本方面,每個節點的計算晶圓成本都比較昂貴,內存人員也在利用人工智能的需求。
Raja Koduri表示,在10 年前,他不會將“封裝”作爲主要成本要素,但現在這是一件大事。除了先進的封裝外,與熱能和電力輸送相關的成本也大幅上升。部分成本在物理上是合理的 - 但其中很大一部分是由生態系統驅動的,試圖在英偉達貪婪的利潤率下支撐他們的利潤率。
在Raja Koduri看來,使用替代封裝方法可以顯著(2-3 倍)降低成本,避免昂貴的有源中介層 + 2.5D/3D 堆疊。但目前尚不清楚它們是否會很快成爲消費者的利益,直到人工智能需求與供應達到更合理的水平。
最後,看看公式的其他部分。

首先看Compatibility(兼容性),這裏涉及有趣的 GPU 歷史。
Raja Koduri介紹,在2002 年,GPU行業引入了 24 位浮點的可編程着色器(與非凡的 ATI R300 一起),並引入了高級着色語言(HLSL、GLSL、Cg),這些語言主要是基於 C 的語言,具有關鍵約束和擴展。這對遊戲引擎开發人員來說是一個福音,我們見證了 2002 年至 2012 年間實時渲染的指數級進步。但是對於熟悉本機 C/C++ 的通用程序員來說,這些語言很尷尬。因此,GPU 主要局限於遊戲开發者。
到了2005 年,高性能 IEEE FP32 的推出引發了 GPGPU 的熱潮——這要歸功於 Mike Houston、Ian Buck 等斯坦福大學校友,他們推動了早期的 GPGPU 語言,如 Brook 和 ATI 提出了一種稱爲 CTM(Close to the metal)的匯編級抽象。雖然這些努力對於演示來說很棒,但它們並沒有越過“兼容性”的門檻,在學術研究之外獲得任何嚴肅的興趣。
而CUDA(以及出色的 Nvidia G80 架構)是第一個將“指針”(pointers)引入 GPU 語言的,並爲 C 程序員提供了更舒適的抽象來使用 GPU。正如他們所說,休息是歷史。指針和虛擬內存支持也是將 GPU 作爲一流的協處理器集成到所有操作系統中的關鍵。這是硬件加速器設計經常忽視的一個方面,這使得爲這些加速器編寫驅動程序成爲軟件工程師的噩夢。
Raja Koduri認爲,CUDA的另一個方面沒有得到廣泛的贊賞。如她所說,CUDA 編程模型是 NVIDIA GPU HW 執行模型的真正抽象。硬件和軟件是共同設計的,並系在HIP(原文:The hardware and software are co-designed and tied at the hip)。雖然許多像 SPMD 這樣的 CUDA 模型都具有可移植性(OpenCL、Sycl、OpenMP、HIP-RocM...),但實現性能可移植性幾乎是不可能的(除非您的架構是精確復制的 CUDA GPU 執行模型)。鑑於涉足 GPU 的程序員將加速作爲主要目標,無法幫助您高效地實現良好性能的語言和工具無法獲得 CUDA 的吸引力。
“CUDA 程序員與 Python/Pytorch 程序員之間有一個有趣的對比 - 但這是另一個時間的线程”,Raja Koduri說。
Raja Koduri承認,CUDA 改進了 GPU 通用性以吸引 C/C++ 程序員。
“對於誕生於python時代的下一代硬件架構師來說,下一個成功的軟硬件協同設計會是什么?”Raja Koduri接着說。
來到Extensibility(擴展)方面。
Raja Koduri表示,GPU 架構以增量方式擴展了很多次。我發現令人驚訝的是,我們仍然可以在現代 GPU 上運行 20+ 年前構建的遊戲二進制文件。雖然在微觀架構方面取得了許多進步,但宏觀層面看起來仍然是一樣的。我們添加了許多新的數據類型、格式、指令擴展,同時保持兼容性。甚至在保留 SPMD 模型的同時添加了張量單元。這種可擴展性使 GPU 能夠快速適應新的工作負載趨勢。
一些專家批評 GPU 對於純張量數學來說非常“低效”——提出並構建了與 GPU 架構不兼容的替代架構。然而,我們仍在等待這些架構之一產生有意義的影響。
再看Accessibility(可及性)方面。
在Raja Koduri看來,這是 GPU 最被低估的優勢。您的架構需要可供所有地區的廣大开發人員訪問。在這方面,遊戲GPU對Nvidia來說是一個巨大的福音。我們經常看到世界各地的年輕大學生通過筆記本電腦或台式機中的 3060 等中端遊戲 GPU 开始首次體驗 GPU 加速。Nvidia 在使其开發人員 SDK 可在裝有 Windows 和 Linux 的 PC 上訪問方面做得非常出色。
但Raja Koduri認爲,對計算和帶寬的需求每年增長 3-4 倍。根據這裏列出的第一個原則,CUDA GPU 硬件將被中斷。唯一的問題是“誰”和“何時”?

在回答讀者的問題時,Raja Koduri表示,Python 和內存是他認爲CUDA GPU將會被顛覆的底氣。
軟件將成爲新焦點
而在AMD最近收購 Silo AI之後,有分析師認爲,軟件已成爲焦點,人工智能芯片战場發生變化。分析師認爲,這一战略轉變正在重新定義人工智能競賽,其中軟件專業知識變得與硬件實力一樣重要。
分析師表示,AMD 最近收購了歐洲最大的私人 AI 實驗室 Silo AI,這體現了這一趨勢。Silo AI 在开發和部署 AI 模型方面擁有豐富的經驗,尤其是大型語言模型(LLM),這是 AMD 關注的一個關鍵領域。
此次收購不僅增強了 AMD 的 AI 軟件能力,也加強了其在歐洲市場的地位,Silo AI 在歐洲市場以开發文化相關的 AI 解決方案而享有盛譽。
Counterpoint Research 合夥人兼聯合創始人 Neil Shah 表示:“Silo AI 填補了 AMD 從軟件工具(Silo OS)到服務(MLOps)的重要能力空白,幫助定制主權和开源 LLM,同時擴大其在重要歐洲市場的影響力。”
AMD 此前已收購 Mipsology 和 Nod.ai,進一步鞏固了其致力於打造強大 AI 軟件生態系統的承諾。Mipsology 在 AI 模型優化和編譯器技術方面的專業知識,加上 Nod.ai 對开源 AI 軟件开發的貢獻,爲 AMD 提供了一套全面的工具和專業知識,以加速其 AI 战略。
Cyber media Research 行業研究組副總裁 Prabhu Ram 表示:“這些战略舉措增強了 AMD 爲尋求跨平台靈活性和互操作性的企業提供定制开源解決方案的能力。通過整合 Silo AI 的功能,AMD 旨在提供一套全面的套件,用於开發、部署和管理 AI 系統,廣泛滿足不同客戶的需求。這符合 AMD 作爲可訪問和开放 AI 解決方案提供商不斷發展的市場地位,充分利用行業對开放性和互操作性的趨勢。”
這種向軟件的战略轉變並不局限於AMD。其他芯片巨頭如Nvidia和Intel也在積極投資軟件公司並开發自己的軟件堆棧。
Shah 表示:“如果你看看 Nvidia 的成功,你會發現它不是由硅片驅動的,而是由其在計算平台上提供的軟件(CUDA)和服務(帶有 MLOps、TAO 等的 NGC)驅動的。”“AMD 意識到了這一點,並一直在投資構建軟件(ROCm、Ryzen Aim 等)和服務(Vitis)功能,爲客戶提供端到端解決方案,以加速 AI 解決方案的开發和部署。”
Nvidia 最近收購了 Run:ai 和 Shoreline.io,這兩家公司均專注於 AI 工作負載管理和基礎設施優化,這也凸顯了軟件在最大限度提高 AI 系統性能和效率方面的重要性。
但這並不意味着芯片制造商會遵循類似的軌跡來實現目標。Techinsights 的半導體分析師 Manish Rawat 指出,在很大程度上,Nvidia 的 AI 生態系統是通過專有技術和強大的开發者社區建立起來的,這使其在 AI 驅動的行業中站穩了腳跟。
Rawat 補充道:“AMD 與 Silo AI 的合作表明,AMD 將集中精力擴展其在 AI 軟件方面的能力,在不斷發展的 AI 領域與 Nvidia 展开競爭。”
另一個相關的例子是英特爾收購實時持續優化軟件提供商 Granulate Cloud Solutions。Granulate 幫助雲和數據中心客戶優化計算工作負載性能,同時降低基礎設施和雲費用。
芯片和軟件專業知識的融合不僅是爲了趕上競爭對手,還爲了推動人工智能領域的創新和差異化。
軟件在優化特定硬件架構的 AI 模型、提高性能和降低成本方面發揮着至關重要的作用。最終,軟件可以決定誰主宰 AI 芯片市場。
Amalgam Insights 首席執行官兼首席分析師 Hyoun Park 表示:“從更大角度來看,AMD 顯然正在與 NVIDIA 爭奪 AI 領域的霸主地位。歸根結底,這不僅僅是誰制造出更好的硬件的問題,而是誰能夠真正支持部署高性能、管理良好且易於長期支持的企業級解決方案。盡管 Lisa Su 和 Jensen Huang 都是科技界最聰明的高管之一,但只有其中一人能夠最終贏得這場战爭,成爲 AI 硬件市場的領導者。”
軟件專業知識與芯片公司產品的整合正在催生全棧 AI 解決方案。這些解決方案涵蓋從硬件加速器和軟件框架到开發工具和服務的所有內容。
通過提供全面的 AI 功能,芯片制造商可以滿足更廣泛的客戶和用例,從基於雲的 AI 服務到邊緣 AI 應用。
例如,Shah 表示,Silo AI 首先帶來了經驗豐富的人才庫,尤其是致力於優化 AI 模型、量身定制的 LLM 等。Silo AI 的 SIloOS 是 AMD 產品的一個非常強大的補充,允許其客戶利用先進的工具和模塊化軟件組件來定制符合其需求的 AI 解決方案。這對 AMD 來說是一個巨大的差距。
Shah 補充道:“第三,Silo AI 還引入了 MLOps 功能,這對於平台參與者來說是一項關鍵功能,可以幫助其企業客戶以可擴展的方式部署、改進和運營 AI 模型。這將幫助 AMD 在軟件和硅片基礎設施之上开發服務層。”
芯片制造商從單純提供硬件轉向提供軟件工具包和服務,這對企業科技公司產生了重大影響。
Shah 強調,這些發展對於企業和人工智能开發人員微調他們的人工智能模型以增強特定芯片上的性能至關重要,適用於訓練和推理階段。
這一進步不僅加快了產品的上市時間,而且還幫助合作夥伴(無論是超大規模企業還是管理內部部署基礎設施)通過改善能源使用和優化代碼來提高運營效率並降低總擁有成本 (TCO)。
“此外,對於芯片制造商來說,這是一種很好的方式,可以將這些开發人員鎖定在他們的平台和生態系統中,並在其基礎上通過軟件工具包和服務獲利。這還可以帶來經常性收入,芯片制造商可以再投資並提高利潤,投資者喜歡這種模式,”Shah 說。
隨着人工智能競賽的不斷發展,對軟件的關注必將加劇。芯片制造商將繼續投資軟件公司,开發自己的軟件堆棧,並與更廣泛的人工智能社區合作,打造一個充滿活力和創新的人工智能生態系統。
人工智能的未來不僅在於更快的芯片,還在於更智能的軟件,它可以釋放人工智能的全部潛力並改變我們的生活和工作方式。
綜上所述,大家認爲GPU主導的市場,會被顛覆嗎?
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。
標題:GPU,獨孤求敗?
地址:https://www.twnewsletter.com/article/44793.html